1 The Whole Game
Spoiler alert!
This chapter runs through the development of a small toy package. It’s meant to paint the Big Picture and suggest a workflow, before we descend into the detailed treatment of the key components of an R package.
To keep the pace brisk, we exploit the modern conveniences in the devtools package and the RStudio IDE. In later chapters, we are more explicit about what those helpers are doing for us.
This chapter is self-contained, in that completing the exercise is not a strict requirement to continue with the rest of the book, however we strongly suggest you follow along and create this toy package with us.
1.1 Load devtools and friends
You can initiate your new package from any active R session. You don’t need to worry about whether you’re in an existing or new project or not. The functions we use ensure that we create a new clean project for the package.
Load the devtools package, which is the public face of a set of packages that support various aspects of package development. The most obvious of these is the usethis package, which you’ll see is also being loaded.
Do you have an old version of devtools? Compare your version against ours and upgrade if necessary.
packageVersion("devtools")
#> [1] '2.5.2'1.2 Toy package: regexcite
To help walk you through the process, we use various functions from devtools to build a small toy package from scratch, with features commonly seen in released packages:
- Functions to address a specific need, in this case helpers for work with regular expressions.
- Version control and an open development process.
- This is completely optional in your work, but highly recommended. You’ll see how Git and GitHub help us expose all the intermediate stages of our toy package.
- Access to established workflows for installation, getting help, and checking quality.
We call the package regexcite and it contains a couple of functions that make common tasks with regular expressions easier. Please note that these functions are very simple and we’re only using them here as a means to guide you through the package development process. If you’re looking for actual helpers for work with regular expressions, there are several proper R packages that address this problem space:
Again, the regexcite package itself is just a device for demonstrating a typical workflow for package development with devtools.
1.3 Preview the finished product
The regexcite package is tracked during its development with the Git version control system. This is purely optional and you can certainly follow along without implementing this. A nice side benefit is that we eventually connect it to a remote repository on GitHub, which means you can see the glorious result we are working towards by visiting regexcite on GitHub: https://github.com/jennybc/regexcite. By inspecting the commit history and especially the diffs, you can see exactly what changes at each step of the process laid out below.
1.4 create_package()
Call create_package() to initialize a new package in a directory on your computer. create_package() will automatically create that directory if it doesn’t exist yet (and that is usually the case). See Section 4.1 for more on creating packages.
Make a deliberate choice about where to create this package on your computer. It should probably be somewhere within your home directory, alongside your other R projects. It should not be nested inside another RStudio Project, R package, or Git repo. Nor should it be in an R package library, which holds packages that have already been built and installed. The conversion of the source package we create here into an installed package is part of what devtools facilitates. Don’t try to do devtools’ job for it!
Once you’ve selected where to create this package, substitute your chosen path into a create_package() call like this:
create_package("~/path/to/regexcite")For the creation of this book we have to work in a temporary directory, because the book is built non-interactively in the cloud. Behind the scenes, we’re executing our own create_package() command, but don’t be surprised if our output differs a bit from yours.
#> ✔ Creating '/tmp/RtmpDM7ewi/regexcite/'.
#> ✔ Setting active project to "/tmp/RtmpDM7ewi/regexcite".
#> ✔ Creating 'R/'.
#> ✔ Writing 'DESCRIPTION'.
#> Package: regexcite
#> Title: What the Package Does (One Line, Title Case)
#> Version: 0.0.0.9000
#> Authors@R (parsed):
#> * First Last <first.last@example.com> [aut, cre]
#> Description: What the package does (one paragraph).
#> License: `use_mit_license()`, `use_gpl3_license()` or friends to pick a
#> license
#> Encoding: UTF-8
#> Roxygen: list(markdown = TRUE)
#> RoxygenNote: 8.0.0
#> ✔ Writing 'NAMESPACE'.
#> ✔ Writing 'regexcite.Rproj'.
#> ✔ Adding "^regexcite\\.Rproj$" to '.Rbuildignore'.
#> ✔ Adding ".Rproj.user" to '.gitignore'.
#> ✔ Adding "^\\.Rproj\\.user$" to '.Rbuildignore'.
#> ✔ Setting active project to "<no active project>".If you’re working in RStudio, you should find yourself in a new instance of RStudio, opened into your new regexcite package (and Project). If you somehow need to do this manually, navigate to the directory and double click on regexcite.Rproj. RStudio has special handling for packages and you should now see a Build tab in the same pane as Environment and History.
You probably need to call library(devtools) again, because create_package() has probably dropped you into a fresh R session, in your new package.
What’s in this new directory that is also an R package and, probably, an RStudio Project? Here’s a listing (locally, you can consult your Files pane):
| path | type |
|---|---|
| .Rbuildignore | file |
| .gitignore | file |
| DESCRIPTION | file |
| NAMESPACE | file |
| R | directory |
| regexcite.Rproj | file |
In the Files pane, go to More (gear symbol) > Show Hidden Files to toggle the visibility of hidden files (a.k.a. “dotfiles”). A select few are visible all the time, but sometimes you want to see them all.
-
.Rbuildignorelists files that we need to have around but that should not be included when building the R package from source. If you aren’t using RStudio,create_package()may not create this file (nor.gitignore) at first, since there’s no RStudio-related machinery that needs to be ignored. However, you will likely develop the need for.Rbuildignoreat some point, regardless of what editor you are using. It is discussed in more detail in Section 3.3.1. -
.Rproj.user, if you have it, is a directory used internally by RStudio. -
.gitignoreanticipates Git usage and tells Git to ignore some standard, behind-the-scenes files created by R and RStudio. Even if you do not plan to use Git, this is harmless. -
DESCRIPTIONprovides metadata about your package. We edit this shortly and Chapter 9 covers the general topic of theDESCRIPTIONfile. -
NAMESPACEdeclares the functions your package exports for external use and the external functions your package imports from other packages. At this point, it is empty, except for a comment declaring that this is a file you should not edit by hand. - The
R/directory is the “business end” of your package. It will soon contain.Rfiles with function definitions. -
regexcite.Rprojis the file that makes this directory an RStudio Project. Even if you don’t use RStudio, this file is harmless. Or you can suppress its creation withcreate_package(..., rstudio = FALSE). More in Section 4.2.
1.5 use_git()
The regexcite directory is an R source package and an RStudio Project. Now we make it also a Git repository, with use_git(). (By the way, use_git() works in any project, regardless of whether it’s an R package.)
use_git()
#> ✔ Initialising Git repo.
#> ✔ Adding ".Rhistory", ".RData", ".httr-oauth", ".DS_Store", and
#> ".quarto" to '.gitignore'.In an interactive session, you will be asked if you want to commit some files here and you should accept the offer. Behind the scenes, we’ll also commit those same files.
So what has changed in the package? Only the creation of a .git directory, which is hidden in most contexts, including the RStudio file browser. Its existence is evidence that we have indeed initialized a Git repo here.
| path | type |
|---|---|
| .git | directory |
If you’re using RStudio, it probably requested permission to relaunch itself in this Project, which you should do. You can do so manually by quitting, then relaunching RStudio by double clicking on regexcite.Rproj. Now, in addition to package development support, you have access to a basic Git client in the Git tab of the Environment/History/Build pane.
Click on History (the clock icon in the Git pane) and, if you consented, you will see an initial commit made via use_git():
| commit | author | message |
|---|---|---|
| 83d70cf392… | jennybc jennybc@users.noreply.github.com | Initial commit |
RStudio can initialize a Git repository, in any Project, even if it’s not an R package, as long you’ve set up RStudio + Git integration. Do Tools > Version Control > Project Setup. Then choose Version control system: Git and initialize a new git repository for this project.
1.6 Write the first function
A fairly common task when dealing with strings is the need to split a single string into many parts. The strsplit() function in base R does exactly this.
(x <- "alfa,bravo,charlie,delta")
#> [1] "alfa,bravo,charlie,delta"
strsplit(x, split = ",")
#> [[1]]
#> [1] "alfa" "bravo" "charlie" "delta"Take a close look at the return value.
The shape of this return value often surprises people or, at least, inconveniences them. The input is a character vector of length one and the output is a list of length one. This makes total sense in light of R’s fundamental tendency towards vectorization. But sometimes it’s still a bit of a bummer. Often you know that your input is morally a scalar, i.e. it’s just a single string, and really want the output to be the character vector of its parts.
This leads R users to employ various methods of “unlist”-ing the result:
The second, safer solution is the basis for the inaugural function of regexcite: strsplit1().
strsplit1 <- function(x, split) {
strsplit(x, split = split)[[1]]
}This book does not teach you how to write functions in R. To learn more about that take a look at the Functions chapter of R for Data Science and the Functions chapter of Advanced R.
The name of strsplit1() is a nod to the very handy paste0(), which first appeared in R 2.15.0 in 2012. paste0() was created to address the extremely common use case of paste()-ing strings together without a separator. paste0() has been lovingly described as “statistical computing’s most influential contribution of the 21st century”.
The strsplit1() function was so inspiring that it’s now a real function in the stringr package: stringr::str_split_1()!
1.7 use_r()
Where should you put the definition of strsplit1()? Save it in a .R file, in the R/ subdirectory of your package. A reasonable starting position is to make a new .R file for each user-facing function in your package and name the file after the function. As you add more functions, you’ll want to relax this and begin to group related functions together. We’ll save the definition of strsplit1() in the file R/strsplit1.R.
The helper use_r() creates and/or opens a script below R/. It really shines in a more mature package, when navigating between .R files and the associated test file. But, even here, it’s useful to keep yourself from getting too carried away while working in Untitled4.
use_r("strsplit1")
#> ☐ Edit 'R/strsplit1.R'.Put the definition of strsplit1() and only the definition of strsplit1() in R/strsplit1.R and save it. The file R/strsplit1.R should NOT contain any of the other top-level code we have recently executed, such as the definition of our practice input x, library(devtools), or use_git(). This foreshadows an adjustment you’ll need to make as you transition from writing R scripts to R packages. Packages and scripts use different mechanisms to declare their dependency on other packages and to store example or test code. We explore this further in Chapter 6.
1.8 load_all()
How do we test drive strsplit1()? If this were a regular R script, we might use RStudio to send the function definition to the R Console and define strsplit1() in the global environment. Or maybe we’d call source("R/strsplit1.R"). For package development, however, devtools offers a more robust approach.
Call load_all() to make strsplit1() available for experimentation.
load_all()
#> ℹ Loading regexciteNow call strsplit1(x) to see how it works.
(x <- "alfa,bravo,charlie,delta")
#> [1] "alfa,bravo,charlie,delta"
strsplit1(x, split = ",")
#> [1] "alfa" "bravo" "charlie" "delta"Note that load_all() has made the strsplit1() function available, although it does not exist in the global environment.
If you see TRUE instead of FALSE, that indicates you’re still using a script-oriented workflow and sourcing your functions. Here’s how to get back on track:
- Clean out the global environment and restart R.
- Re-attach devtools with
library(devtools)and re-load regexcite withload_all(). - Redefine the test input
xand callstrsplit1(x, split = ",")again. This should work! - Run
exists("strsplit1", where = globalenv(), inherits = FALSE)again and you should seeFALSE.
load_all() simulates the process of building, installing, and attaching the regexcite package. As your package accumulates more functions, some exported, some not, some of which call each other, some of which call functions from packages you depend on, load_all() gives you a much more accurate sense of how the package is developing than test driving functions defined in the global environment. Also load_all() allows much faster iteration than actually building, installing, and attaching the package. See Section 4.4 for more about load_all().
To review what we’ve done so far:
- We wrote our first function,
strsplit1(), to split a string into a character vector (not a list containing a character vector). - We used
load_all()to quickly make this function available for interactive use, as if we’d built and installed regexcite and attached it vialibrary(regexcite).
RStudio exposes load_all() in the Build menu, in the Build pane via More > Load All, and in keyboard shortcuts Ctrl + Shift + L (Windows & Linux) or Cmd + Shift + L (macOS).
1.8.1 Commit strsplit1()
If you’re using Git, use your preferred method to commit the new R/strsplit1.R file. We do so behind the scenes here and here’s the associated diff.
diff --git a/R/strsplit1.R b/R/strsplit1.R
new file mode 100644
index 0000000..29efb88
--- /dev/null
+++ b/R/strsplit1.R
@@ -0,0 +1,3 @@
+strsplit1 <- function(x, split) {
+ strsplit(x, split = split)[[1]]
+}From this point on, we commit after each step. Remember these commits are available in the public repository.
1.9 check()
We have informal, empirical evidence that strsplit1() works. But how can we be sure that all the moving parts of the regexcite package still work? This may seem silly to check, after such a small addition, but it’s good to establish the habit of checking this often.
R CMD check, executed in the shell, is the gold standard for checking that an R package is in full working order. check() is a convenient way to run this without leaving your R session.
Note that check() produces rather voluminous output, optimized for interactive consumption. We intercept that here and just reveal a summary. Your local check() output will be different.
check()── R CMD check results ─────────────────── regexcite 0.0.0.9000 ────
Duration: 6.7s
❯ checking DESCRIPTION meta-information ... WARNING
Non-standard license specification:
`use_mit_license()`, `use_gpl3_license()` or friends to pick a
license
Standardizable: FALSE
0 errors ✔ | 1 warning ✖ | 0 notes ✔It is essential to actually read the output of the check! Deal with problems early and often. It’s just like incremental development of .R and .Rmd files. The longer you go between full checks that everything works, the harder it becomes to pinpoint and solve your problems.
At this point, we expect 1 warning (and 0 errors, 0 notes):
Non-standard license specification:
`use_mit_license()`, `use_gpl3_license()` or friends to pick a
licenseWe’ll address that soon, by doing exactly what it says. You can learn more about check() in Section 4.5.
RStudio exposes check() in the Build menu, in the Build pane via Check, and in keyboard shortcuts Ctrl + Shift + E (Windows & Linux) or Cmd + Shift + E (macOS).
1.10 Edit DESCRIPTION
The DESCRIPTION file provides metadata about your package and is covered fully in Chapter 9. This is a good time to have a look at regexcite’s current DESCRIPTION. You’ll see it’s populated with boilerplate content, which needs to be replaced.
To add your own metadata, make these edits:
- Make yourself the author. If you don’t have an ORCID, you can omit the
comment = ...portion. - Write some descriptive text in the
TitleandDescriptionfields.
Use Ctrl + . in RStudio and start typing “DESCRIPTION” to activate a helper that makes it easy to open a file for editing. In addition to a filename, your hint can be a function name. This is very handy once a package has lots of files.
When you’re done, DESCRIPTION should look similar to this:
Package: regexcite
Title: Make Regular Expressions More Exciting
Version: 0.0.0.9000
Authors@R:
person("Jane", "Doe", , "jane@example.com", role = c("aut", "cre"))
Description: Convenience functions to make some common tasks with string
manipulation and regular expressions a bit easier.
License: `use_mit_license()`, `use_gpl3_license()` or friends to pick a
license
Encoding: UTF-8
Roxygen: list(markdown = TRUE)
RoxygenNote: 7.1.2
1.11 use_mit_license()
We currently have a placeholder in the License field of DESCRIPTION that’s deliberately invalid and suggests a resolution.
License: `use_mit_license()`, `use_gpl3_license()` or friends to pick a
licenseTo configure a valid license for the package, call use_mit_license().
use_mit_license()
#> ✔ Adding "MIT + file LICENSE" to 'License'.
#> ✔ Writing 'LICENSE'.
#> ✔ Writing 'LICENSE.md'.
#> ✔ Adding "^LICENSE\\.md$" to '.Rbuildignore'.This configures the License field correctly for the MIT license, which promises to name the copyright holders and year in a LICENSE file. Open the newly created LICENSE file and confirm it looks something like this:
YEAR: 2026
COPYRIGHT HOLDER: regexcite authorsLike other license helpers, use_mit_license() also puts a copy of the full license in LICENSE.md and adds this file to .Rbuildignore. It’s considered a best practice to include a full license in your package’s source, such as on GitHub, but CRAN disallows the inclusion of this file in a package tarball. You can learn more about licensing in Chapter 12.
1.12 document()
Wouldn’t it be nice to get help on strsplit1(), just like we do with other R functions? This requires that your package have a special R documentation file, man/strsplit1.Rd, written in an R-specific markup language that is sort of like LaTeX. Luckily we don’t necessarily have to author that directly.
We write a specially formatted comment right above strsplit1(), in its source file, and then let a package called roxygen2 handle the creation of man/strsplit1.Rd. The motivation and mechanics of roxygen2 are covered in Chapter 16.
If you use RStudio, open R/strsplit1.R in the source editor and put the cursor somewhere in the strsplit1() function definition. Now do Code > Insert roxygen skeleton. A very special comment should appear above your function, in which each line begins with #'. RStudio only inserts a barebones template, so you will need to edit it to look something like that below.
If you don’t use RStudio, create the comment yourself. Regardless, you should modify it to look something like this:
#' Split a string
#'
#' @param x A character vector with one element.
#' @param split What to split on.
#'
#' @return A character vector.
#' @export
#'
#' @examples
#' x <- "alfa,bravo,charlie,delta"
#' strsplit1(x, split = ",")
strsplit1 <- function(x, split) {
strsplit(x, split = split)[[1]]
}But we’re not done yet! We still need to trigger the conversion of this new roxygen comment into man/strsplit1.Rd with document():
document()
#> ℹ Updating regexcite documentation
#> ℹ Setting Config/roxygen2/version to "8.0.0"
#> ℹ Loading regexcite
#> Writing 'NAMESPACE'
#> Writing 'strsplit1.Rd'RStudio exposes document() in the Build menu, in the Build pane via More > Document, and in keyboard shortcuts Ctrl + Shift + D (Windows & Linux) or Cmd + Shift + D (macOS).
You should now be able to preview your help file like so:
?strsplit1You’ll see a message like “Rendering development documentation for ‘strsplit1’”, which reminds that you are basically previewing draft documentation. That is, this documentation is present in your package’s source, but is not yet present in an installed package. In fact, we haven’t installed regexcite yet, but we will soon. If ?strsplit1 doesn’t work for you, you may need to call load_all() first, then try again.
Note also that your package’s documentation won’t be properly wired up until it has been formally built and installed. This polishes off niceties like the links between help files and the creation of a package index.
1.12.1 NAMESPACE changes
In addition to converting strsplit1()’s special comment into man/strsplit1.Rd, the call to document() updates the NAMESPACE file, based on @export tags found in roxygen comments. Open NAMESPACE for inspection. The contents should be:
# Generated by roxygen2: do not edit by hand
export(strsplit1)The export directive in NAMESPACE is what makes strsplit1() available to a user after attaching regexcite via library(regexcite). Just as it is entirely possible to author .Rd files “by hand”, you can manage NAMESPACE explicitly yourself. But we choose to delegate this to devtools (and roxygen2).
1.13 check() again
regexcite should pass R CMD check cleanly now and forever more: 0 errors, 0 warnings, 0 notes.
check()── R CMD check results ─────────────────── regexcite 0.0.0.9000 ────
Duration: 7.8s
0 errors ✔ | 0 warnings ✔ | 0 notes ✔
1.14 install()
Now that we know we have a minimum viable product, let’s install the regexcite package into your library via install():
install()── pak::local_install_deps() ───────────────────────────────────────
── R CMD build ─────────────────────────────────────────────────────
* checking for file ‘/tmp/RtmpDM7ewi/regexcite/DESCRIPTION’ ... OK
* preparing ‘regexcite’:
* checking DESCRIPTION meta-information ... OK
* checking for LF line-endings in source and make files and shell scripts
* checking for empty or unneeded directories
* building ‘regexcite_0.0.0.9000.tar.gz’
── R CMD INSTALL ───────────────────────────────────────────────────
Running /opt/R/4.6.1/lib/R/bin/R CMD INSTALL \
/tmp/RtmpDM7ewi/regexcite_0.0.0.9000.tar.gz --install-tests
* installing to library ‘/home/runner/work/_temp/Library’
* installing *source* package ‘regexcite’ ...
** this is package ‘regexcite’ version ‘0.0.0.9000’
** using staged installation
** R
** byte-compile and prepare package for lazy loading
** help
*** installing help indices
** building package indices
** testing if installed package can be loaded from temporary location
** testing if installed package can be loaded from final location
** testing if installed package keeps a record of temporary installation path
* DONE (regexcite)
→ Package library at '/home/runner/work/_temp/Library', '/opt/R/4.6.1/lib/R/site-library', and '/opt/R/4.6.1/lib/R/library'.
→ Will download 1 package with unknown size.
ℹ No downloads are needed
✔ : [2.1s]RStudio exposes similar functionality in the Build menu and in the Build pane via Install and Restart, and in keyboard shortcuts Ctrl + Shift + B (Windows & Linux) or Cmd + Shift + B (macOS).
After installation is complete, we can attach and use regexcite like any other package. Let’s revisit our small example from the top. This is also a good time to restart your R session and ensure you have a clean workspace.
library(regexcite)
x <- "alfa,bravo,charlie,delta"
strsplit1(x, split = ",")
#> [1] "alfa" "bravo" "charlie" "delta"Success!
1.15 use_testthat()
We’ve tested strsplit1() informally, in a single example. We can formalize this as a unit test. This means we express a concrete expectation about the correct strsplit1() result for a specific input.
First, we declare our intent to write unit tests and to use the testthat package for this, via use_testthat():
use_testthat()
#> ✔ Adding testthat to 'Suggests' field in DESCRIPTION.
#> ✔ Adding "3" to 'Config/testthat/edition'.
#> ✔ Creating 'tests/testthat/'.
#> ✔ Writing 'tests/testthat.R'.
#> ☐ Call `usethis::use_test()` to initialize a basic test file and
#> open it for editing.This initializes the unit testing machinery for your package. It adds Suggests: testthat to DESCRIPTION, creates the directory tests/testthat/, and adds the script tests/testthat.R. You’ll notice that testthat is probably added with a minimum version of 3.0.0 and a second DESCRIPTION field, Config/testthat/edition: 3. We’ll talk more about those details in Chapter 13.
However, it’s still up to YOU to write the actual tests!
The helper use_test() opens and/or creates a test file. You can provide the file’s basename or, if you are editing the relevant source file in RStudio, it will be automatically generated. For many of you, if R/strsplit1.R is the active file in RStudio, you can just call use_test(). However, since this book is built non-interactively, we must provide the basename explicitly:
use_test("strsplit1")
#> ✔ Writing 'tests/testthat/test-strsplit1.R'.
#> ☐ Edit 'tests/testthat/test-strsplit1.R'.This creates the file tests/testthat/test-strsplit1.R. If it had already existed, use_test() would have just opened it. You will notice that there is an example test in the newly created file - delete that code and replace it with this content:
test_that("strsplit1() splits a string", {
expect_equal(strsplit1("a,b,c", split = ","), c("a", "b", "c"))
})This tests that strsplit1() gives the expected result when splitting a string.
Run this test interactively, as you will when you write your own. If test_that() or strsplit1() can’t be found, that suggests that you probably need to call load_all().
Going forward, your tests will mostly run en masse and at arm’s length via test():
test()
#> ℹ Testing regexcite
#> ✔ | F W S OK | Context
#>
#> ⠏ | 0 | strsplit1
#> ✔ | 1 | strsplit1
#>
#> ══ Results ═════════════════════════════════════════════════════════
#> [ FAIL 0 | WARN 0 | SKIP 0 | PASS 1 ]
#>
#> Keep up the good work.RStudio exposes test() in the Build menu, in the Build pane via More > Test package, and in keyboard shortcuts Ctrl + Shift + T (Windows & Linux) or Cmd + Shift + T (macOS).
Your tests are also run whenever you check() the package. In this way, you basically augment the standard checks with some of your own, that are specific to your package. It is a good idea to use the covr package to track what proportion of your package’s source code is exercised by the tests. More details can be found in Section 14.1.1.
1.16 use_package()
You will inevitably want to use a function from another package in your own package. We will need to use package-specific methods for declaring the other packages we need (i.e. our dependencies) and for using these packages in ours. If you plan to submit a package to CRAN, note that this even applies to functions in packages that you think of as “always available”, such as stats::median() or utils::head().
One common dilemma when using R’s regular expression functions is uncertainty about whether to request perl = TRUE or perl = FALSE. And then there are often, but not always, other arguments that alter how patterns are matched, such as fixed, ignore.case, and invert. It can be hard to keep track of which functions use which arguments and how the arguments interact, so many users never get to the point where they retain these details without rereading the docs.
The stringr package “provides a cohesive set of functions designed to make working with strings as easy as possible”. In particular, stringr uses one regular expression system everywhere (ICU regular expressions) and uses the same interface in every function for controlling matching behaviors, such as case sensitivity. Some people find this easier to internalize and program around. Let’s imagine you decide you’d rather build regexcite based on stringr (and stringi) than base R’s regular expression functions.
First, declare your general intent to use some functions from the stringr namespace with use_package():
use_package("stringr")
#> ✔ Adding stringr to 'Imports' field in DESCRIPTION.
#> ☐ Refer to functions with `stringr::fun()`.This adds the stringr package to the Imports field of DESCRIPTION. And that is all it does.
Let’s revisit strsplit1() to make it more stringr-like. Here’s a new take on it1:
Notice that we:
- Rename the function to
str_split_one(), to signal that it is a wrapper aroundstringr::str_split(). - Adopt the argument names from
stringr::str_split(). Now we havestringandpattern(andn), instead ofxandsplit. - Introduce a bit of argument checking and edge case handling. This is unrelated to the switch to stringr and would be equally beneficial in the version built on
strsplit(). - Use the
package::function()form when callingstringr::str_split(). This specifies that we want to call thestr_split()function from the stringr namespace. There is more than one way to call a function from another package and the one we endorse here is explained fully in Chapter 11.
Where should we write this new function definition? If we want to keep following the convention where we name the .R file after the function it defines, we now need to do some fiddly file shuffling. Because this comes up fairly often in real life, we have the rename_files() function, which choreographs the renaming of a file in R/ and its associated companion files below test/.
rename_files("strsplit1", "str_split_one")
#> ✔ Moving 'R/strsplit1.R' to 'R/str_split_one.R'.
#> ✔ Moving 'tests/testthat/test-strsplit1.R' to
#> 'tests/testthat/test-str_split_one.R'.Remember: the file name work is purely aspirational. We still need to update the contents of these files!
Here are the updated contents of R/str_split_one.R. In addition to changing the function definition, we’ve also updated the roxygen header to reflect the new arguments and to include examples that show off the stringr features.
#' Split a string
#'
#' @param string A character vector with, at most, one element.
#' @inheritParams stringr::str_split
#'
#' @return A character vector.
#' @export
#'
#' @examples
#' x <- "alfa,bravo,charlie,delta"
#' str_split_one(x, pattern = ",")
#' str_split_one(x, pattern = ",", n = 2)
#'
#' y <- "192.168.0.1"
#' str_split_one(y, pattern = stringr::fixed("."))
str_split_one <- function(string, pattern, n = Inf) {
stopifnot(is.character(string), length(string) <= 1)
if (length(string) == 1) {
stringr::str_split(string = string, pattern = pattern, n = n)[[1]]
} else {
character()
}
}Don’t forget to also update the test file!
Here are the updated contents of tests/testthat/test-str_split_one.R. In addition to the change in the function’s name and arguments, we’ve added a couple more tests.
test_that("str_split_one() splits a string", {
expect_equal(str_split_one("a,b,c", ","), c("a", "b", "c"))
})
test_that("str_split_one() errors if input length > 1", {
expect_error(str_split_one(c("a,b","c,d"), ","))
})
test_that("str_split_one() exposes features of stringr::str_split()", {
expect_equal(str_split_one("a,b,c", ",", n = 2), c("a", "b,c"))
expect_equal(str_split_one("a.b", stringr::fixed(".")), c("a", "b"))
})Before we take the new str_split_one() out for a test drive, we need to call document(). Why? Remember that document() does two main jobs:
- Converts our roxygen comments into proper R documentation.
- (Re)generates
NAMESPACE.
The second job is especially important here, since we will no longer export strsplit1() and we will newly export str_split_one(). Don’t be dismayed by the warning about "Objects listed as exports, but not present in namespace: strsplit1". That always happens when you remove something from the namespace.
document()
#> ℹ Updating regexcite documentation
#> ℹ Loading regexcite
#> Warning: Objects listed as exports, but not present in namespace:
#> • strsplit1
#> Writing 'NAMESPACE'
#> Writing 'str_split_one.Rd'
#> Deleting 'strsplit1.Rd'Try out the new str_split_one() function by simulating package installation via load_all():
load_all()
#> ℹ Loading regexcite
str_split_one("a, b, c", pattern = ", ")
#> [1] "a" "b" "c"
1.17 use_github()
You’ve seen us making commits during the development process for regexcite. You can see an indicative history at https://github.com/jennybc/regexcite. Our use of version control and the decision to expose the development process means you can inspect the state of the regexcite source at each developmental stage. By looking at so-called diffs, you can see exactly how each devtools helper function modifies the source files that constitute the regexcite package.
How would you connect your local regexcite package and Git repository to a companion repository on GitHub? Here are three approaches:
-
use_github()is a helper that we recommend for the long-term. We won’t demonstrate it here because it requires some credential setup on your end. We also don’t want to tear down and rebuild the public regexcite package every time we build this book. - Set up the GitHub repo first! It sounds counter-intuitive, but the easiest way to get your work onto GitHub is to initiate there, then use RStudio to start working in a synced local copy. This approach is described in Happy Git’s workflows New project, GitHub first and Existing project, GitHub first.
- Command line Git can always be used to add a remote repository post hoc. This is described in the Happy Git workflow Existing project, GitHub last.
Any of these approaches will connect your local regexcite project to a GitHub repo, public or private, which you can push to or pull from using the Git client built into RStudio. In Chapter 20, we elaborate on why version control (e.g., Git) and, specifically, hosted version control (e.g. GitHub) is worth incorporating into your package development process.
1.18 use_readme_rmd()
Now that your package is on GitHub, the README.md file matters. It is the package’s home page and welcome mat, at least until you decide to give it a website (see Chapter 19), add a vignette (see Chapter 17), or submit it to CRAN (see Chapter 22).
The use_readme_rmd() function initializes a basic, executable README.Rmd ready for you to edit:
use_readme_rmd()
#> ✔ Writing 'README.Rmd'.
#> ✔ Adding "^README\\.Rmd$" to '.Rbuildignore'.
#> ☐ Update 'README.Rmd' to include installation instructions.
#> ✔ Writing '.git/hooks/pre-commit'.In addition to creating README.Rmd, this adds some lines to .Rbuildignore, and creates a Git pre-commit hook to help you keep README.Rmd and README.md in sync.
README.Rmd already has sections that prompt you to:
- Describe the purpose of the package.
- Provide installation instructions. If a GitHub remote is detected when
use_readme_rmd()is called, this section is pre-filled with instructions on how to install from GitHub. - Show a bit of usage.
How to populate this skeleton? Copy stuff liberally from DESCRIPTION and any formal and informal tests or examples you have. Anything is better than nothing. This is helpful because people probably won’t install your package and comb through individual help files to figure out how to use it.
We like to write the README in R Markdown, so it can feature actual usage. The inclusion of live code also makes it less likely that your README grows stale and out-of-sync with your actual package.
To make your own edits, if RStudio has not already done so, open README.Rmd for editing. Make sure it shows some usage of str_split_one().
The README.Rmd we use is here: README.Rmd and here’s what it contains:
---
output: github_document
---
<!-- README.md is generated from README.Rmd. Please edit that file -->
```{r, include = FALSE}
knitr::opts_chunk$set(
collapse = TRUE,
comment = "#>",
fig.path = "man/figures/README-",
out.width = "100%"
)
```
**NOTE: This is a toy package created for expository purposes, for the second edition of [R Packages](https://r-pkgs.org). It is not meant to actually be useful. If you want a package for factor handling, please see [stringr](https://stringr.tidyverse.org), [stringi](https://stringi.gagolewski.com/),
[rex](https://cran.r-project.org/package=rex), and
[rematch2](https://cran.r-project.org/package=rematch2).**
# regexcite
<!-- badges: start -->
<!-- badges: end -->
The goal of regexcite is to make regular expressions more exciting!
It provides convenience functions to make some common tasks with string manipulation and regular expressions a bit easier.
## Installation
You can install the development version of regexcite from [GitHub](https://github.com/) with:
``` r
# install.packages("devtools")
devtools::install_github("jennybc/regexcite")
```
## Usage
A fairly common task when dealing with strings is the need to split a single string into many parts.
This is what `base::strplit()` and `stringr::str_split()` do.
```{r}
(x <- "alfa,bravo,charlie,delta")
strsplit(x, split = ",")
stringr::str_split(x, pattern = ",")
```
Notice how the return value is a **list** of length one, where the first element holds the character vector of parts.
Often the shape of this output is inconvenient, i.e. we want the un-listed version.
That's exactly what `regexcite::str_split_one()` does.
```{r}
library(regexcite)
str_split_one(x, pattern = ",")
```
Use `str_split_one()` when the input is known to be a single string.
For safety, it will error if its input has length greater than one.
`str_split_one()` is built on `stringr::str_split()`, so you can use its `n` argument and stringr's general interface for describing the `pattern` to be matched.
```{r}
str_split_one(x, pattern = ",", n = 2)
y <- "192.168.0.1"
str_split_one(y, pattern = stringr::fixed("."))
```Don’t forget to render it to make README.md! The pre-commit hook should remind you if you try to commit README.Rmd, but not README.md, and also when README.md appears to be out-of-date.
The very best way to render README.Rmd is with build_readme(), because it takes care to render with the most current version of your package, i.e. it installs a temporary copy from the current source.
build_readme()
#> ℹ Loading metadata database
#> ✔ Loading metadata database ... done
#> You can see the rendered README.md simply by visiting regexcite on GitHub.
Finally, don’t forget to do one last commit. And push, if you’re using GitHub.
1.19 The end: check() and install()
Let’s run check() again to make sure all is still well.
check()── R CMD check results ─────────────────── regexcite 0.0.0.9000 ────
Duration: 8.9s
0 errors ✔ | 0 warnings ✔ | 0 notes ✔regexcite should have no errors, warnings or notes. This would be a good time to re-build and install it properly. And celebrate!
install()── pak::local_install_deps() ───────────────────────────────────────
── R CMD build ─────────────────────────────────────────────────────
* checking for file ‘/tmp/RtmpDM7ewi/regexcite/DESCRIPTION’ ... OK
* preparing ‘regexcite’:
* checking DESCRIPTION meta-information ... OK
* checking for LF line-endings in source and make files and shell scripts
* checking for empty or unneeded directories
Removed empty directory ‘regexcite/tests/testthat/_snaps’
* building ‘regexcite_0.0.0.9000.tar.gz’
── R CMD INSTALL ───────────────────────────────────────────────────
Running /opt/R/4.6.1/lib/R/bin/R CMD INSTALL \
/tmp/RtmpDM7ewi/regexcite_0.0.0.9000.tar.gz --install-tests
* installing to library ‘/home/runner/work/_temp/Library’
* installing *source* package ‘regexcite’ ...
** this is package ‘regexcite’ version ‘0.0.0.9000’
** using staged installation
** R
** tests
** byte-compile and prepare package for lazy loading
** help
*** installing help indices
** building package indices
** testing if installed package can be loaded from temporary location
** testing if installed package can be loaded from final location
** testing if installed package keeps a record of temporary installation path
* DONE (regexcite)
→ Package library at '/home/runner/work/_temp/Library', '/opt/R/4.6.1/lib/R/site-library', and '/opt/R/4.6.1/lib/R/library'.
→ Will download 1 package with unknown size.
✔ All system requirements are already installed.
ℹ No downloads are needed
ℹ Installing system requirements
ℹ Executing `sudo sh -c apt-get -y update`
Get:1 file:/etc/apt/apt-mirrors.txt Mirrorlist [144 B]
Hit:6 https://packages.microsoft.com/repos/azure-cli noble InRelease
Hit:7 https://packages.microsoft.com/ubuntu/24.04/prod noble InRelease
Hit:2 http://azure.archive.ubuntu.com/ubuntu noble InRelease
Hit:3 http://azure.archive.ubuntu.com/ubuntu noble-updates InRelease
Hit:4 http://azure.archive.ubuntu.com/ubuntu noble-backports InRelease
Hit:5 http://azure.archive.ubuntu.com/ubuntu noble-security InRelease
Hit:8 https://dl.google.com/linux/chrome-stable/deb stable InRelease
Reading package lists...
ℹ Executing `sudo sh -c apt-get -y install libicu-dev`
Reading package lists...
Building dependency tree...
Reading state information...
libicu-dev is already the newest version (74.2-1ubuntu3.1).
0 upgraded, 0 newly installed, 0 to remove and 66 not upgraded.
✔ 8 deps: kept 8 [2.1s]Feel free to visit the regexcite package on GitHub, which appears exactly as developed here. The commit history reflects each individual step, so use the diffs to see the addition and modification of files, as the package evolved. The rest of this book goes in greater detail for each step you’ve seen here and much more.
1.20 Review
This chapter is meant to give you a sense of the typical package development workflow, summarized as a diagram in Figure 1.1. Everything you see here has been touched on in this chapter, with the exception of GitHub Actions, which you will learn more about in Section 20.2.1.
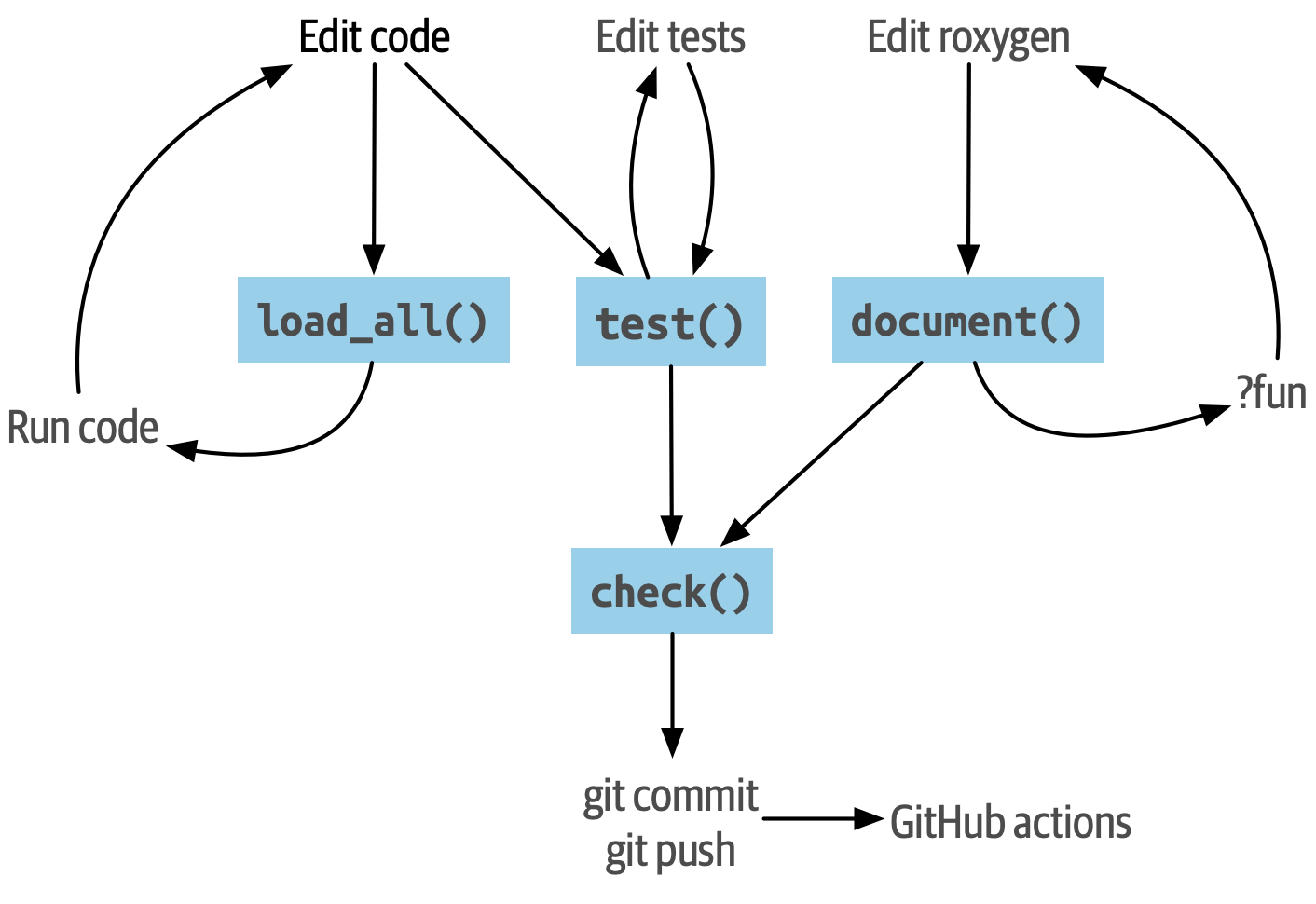
Here is a review of the key functions you’ve seen in this chapter, organized roughly by their role in the development process.
These functions setup parts of the package and are typically called once per package:
You will call these functions on a regular basis, as you add functions and tests or take on dependencies:
You will call these functions multiple times per day or per hour, during development:
Recall that this example was so inspiring that it’s now a real function in the stringr package:
stringr::str_split_1()!↩︎